Multi-Path Payments in LND: Making Channel Balances Add Up
With the release of LND 0.10, one of the most highly anticipated features of Lightning was brought to completion. After an extensive specification and implementation process, we are pleased to announce that LND now fully supports multi-path payments.
In prior versions, every successful payment was accomplished through exactly one successful HTLC: one HTLC, one route, and the full payment amount delivered atomically to the recipient. Simple, fast, but not the optimal way to utilize committed capital.
One scenario where this sub-optimality is apparent is when the sender has enough liquidity in total, but none of their channels can carry the payment amount. In the diagram below, a payment of 30k sats cannot be sent even though the sender has a total of 30k sats in its channels.
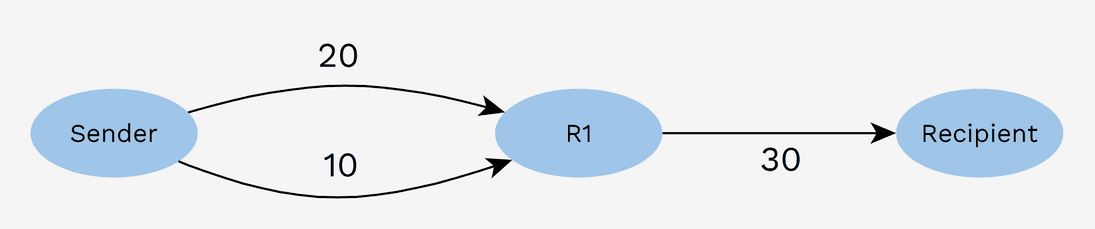
A multi-path payment (MPP) can solve this problem by sending the payment in two parts. The first payment part consumes 20k sats in one channel and the second part uses 10k sats in the other channel. The highest payment amount is now defined by the sum of all channel balances rather than the maximum.
Settling multiple parts
When the recipient receives the first part, they won’t immediately settle the HTLC. Instead the HTLC is accepted and held, similar to how hodl invoice payments are accepted. They could settle because the preimage is known, but that wouldn’t be a rational thing to do. Settling right away would return the proof of payment to the sender while the full amount may never arrive. With the proof of payment, the sender could claim that the payment was made in full. Because all parts use the same payment hash, another possibility that may be even worse is that an intermediate node uses the now public preimage to settle the second HTLC without forwarding at all.
So the recipient waits for the second HTLC to arrive. They then conclude that the full amount has arrived and will at that point settle both HTLCs.
It isn’t necessary for the recipient to know the number of parts upfront. Parts will be accumulated until the expected value is met. Parts aren’t held forever though, because this could intentionally or accidentally lead to funds being locked in an unusable state for longer than necessary. This timeout is implemented as a fixed two-minute timeout per HTLC, meaning that the sender has two minutes to send the complete set of HTLCs to the recipient’s node. If this process fails, the sender can then try again. LND’s Mission Control learns more about the available routes with each attempt, so subsequent attempts are more likely to succeed in time.
Fragmented inbound liquidity
Besides the problem of fragmented outbound liquidity described above, inbound liquidity on the receiver side can also be a problem:
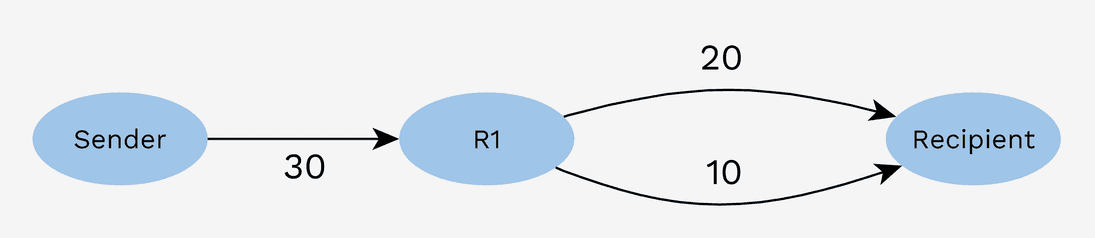
A multi-path payment can also solve the problem in this case. The sender however doesn’t know what the balances between R1 and the recipient are. Correct partial amounts will need to be figured out through trial and error. One can imagine that in this specific case, where there is just a single way of completing the payment, trial and error is a lengthy and impractical process.
An extra complicating factor in this trial and error process is that failures are reported, but successes aren’t. As long as the set is not yet complete, the receiver will hold the HTLC. Unfortunately the sender isn’t able to distinguish this successful outcome from an HTLC that got stuck somewhere midway.
Non-ideal network conditions
A third class of problems potentially solvable with MPP is fragmented liquidity on the routing network.
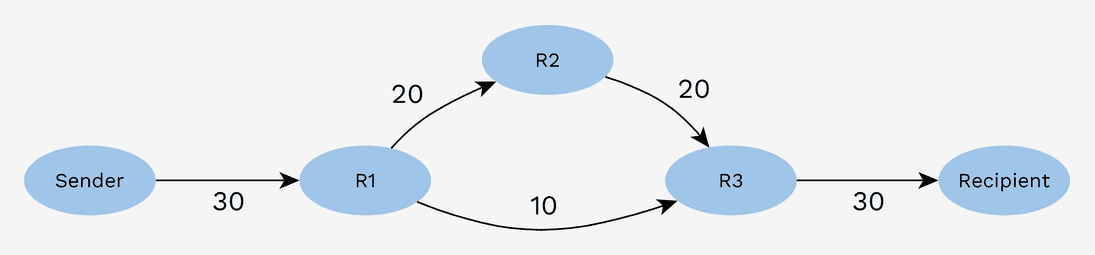
This creates a challenge similar to the inbound liquidity situation. The sender is also in the dark about the actual network channel balances and will need to probe its way to the recipient.
Additional benefits
Completing previously impossible payments is an improvement, but there are more potential benefits to multi-path payments. In general, large capacity channels are relatively scarce. That means that a higher fee can be commanded for traffic through these channels. Sometimes it was necessary for users to raise their fee limit in order to successfully make large payments. With multi-path payments, a lower fee limit may be sufficient because multiple cheap channels can be used together. This change may induce a shift in fee schedules on the network, incentivizing nodes with large capacity channels to lower their rates to remain competitive.
Further downward pressure on fees is created because routing node capital can be utilized more efficiently. The same capital can generate more revenue while costs remain the same. It also makes it more likely that smaller routing nodes with less capital will be able to route profitably, thereby encouraging decentralization.
Another routing optimization target is reliability. Intuitively it would seem that high capacity channels would be reliable. If someone commits significant money to a channel, they will probably make sure that it is functional. But if for some reason that isn’t the case, it is possible that a more reliable payment can be made through a set of smaller channels.
A final benefit of multi-path payments is that it obfuscates payment amounts. If a routing node is connected to a well-known source or destination of payments, it could guess at what the payment amount distribution looks like. Without the assumption that each payment consists of a single HTLC, the guessing becomes harder, enhancing privacy on the network.
Splitting into parts
As mentioned before, the sender has a very limited view of network channel balances and thus uses trial and error to find a partitioning solution that works. This, among other limitations, like the absence of a signal for arrived HTLCs, makes it challenging to find the optimal split. This is an entire research area of its own.
Further, splitting is just a part of building an MPP-enabled Lightning node. There are also specific requirements for matters like persistent storage, reporting, and failure interpretation. For the 0.10 release of LND, we chose to implement all of this supporting functionality while keeping the splitting algorithm itself simple. Our goal is to get early feedback to inform future development.
The chosen algorithm is by no means optimal, but we do expect that it will address the majority of the previously existing problems around fragmented liquidity. The way it works could be described as ‘recursive halvening’.
Initially, LND will try to complete the payment in one part. If that’s not possible, say because channel capacities aren’t sufficient or because other constraints like the fee limit are hit, an attempt is made for half the payment amount. After that HTLC has been launched, the software searches for a second path to pay the remaining amount (the other half). If further failures happen, amounts are repeatedly split until a minimum amount limit is reached or the payment succeeds.
While it may not sound that complicated, the reasoning surrounding the characteristics of this algorithm can be quite involved, especially in combination with the time component (HTLCs are in-flight for some time).
One finding is that it isn’t a good idea to launch too many HTLCs at the same time. In LND, the mission control sub-system tracks balance estimates for network channels. Those estimates are only updated when HTLCs fail or succeed. This takes place when the system knows for sure what happened to a specific HTLC. But this also means that for simultaneously launched HTLCs, the corresponding pathfinding operations will all use the same estimates. It looks as if more of a balance is available than there probably is once the second or third HTLC actually reaches the channel. At that point, the first HTLC has consumed some of the balance already.
This situation with competing HTLCs isn’t critical. Some of the HTLCs will fail, mission control will be updated, and a new attempt will be made. But if you launch huge numbers of HTLCs, it would stress the network, increasing latency and exacerbating the problem.
Going forward, we may investigate the possibility of incorporating data from in-flight HTLCs into mission control estimates, but there are drawbacks to that solution as well. For example, nodes may have multiple channels to a peer. In that case, the HTLC may not lower the available balance by the HTLC amount. An enhancement like this also requires significant implementation effort.
In line with the idea to start simple, we added a mitigating manual control
parameter max_parts. This
limits the maximum number of parts that a payment may consist of and also limits
the maximum number of in-flight HTLCs. Admittedly, in the ideal world this
parameter wouldn’t exist, but given the development time trade-off, we think it
is an acceptable inconvenience for the time being.
Related changes
Payment state updates
With this release, it was inevitable for the payment execution process under the hood to become more complicated, meaning that debugging and getting a sense of what is going on in general is harder as well. The log file as a source of information was never practical, but with parallel HTLCs, it has become close to impossible for the average user to make much use of it.
As a result, we’ve also upgraded the options for payment tracking. It is now possible to receive intermediate payment state updates for every HTLC launched or resolved. This opens the way for user-facing applications to take those updates and provide human-readable visualizations to end users.
One user-facing application is our own command line tool lncli. Lncli has been upgraded to track payment progress in a formatted table.
Invoice amount limit
In LND 0.10 we’ve removed the previously existing invoice and payment amount limit of 4.2M sats. Strictly speaking, this is a change independent of multi-path payments. For single-shot payments, it lifts the maximum amount to 16M sats, assuming there are no wumbo channels (non-standard channels for which both parties agreed to raise the capacity above the current maximum).
For multi-path payments, the maximum payment amount is now only limited by the sum of all liquidity between sender and receiver. With the right channel configuration, you will for example be able to pay one whole bitcoin over Lightning. But keep in mind the limitations of the splitting/probing algorithm. You have to be lucky to be able to make a payment close to the theoretical maximum that the channel configuration allows.
Keysend
Sending “spontaneous” or “Keysend” payments (payments that can be initiated without an invoice) is an important feature for Lightning, especially in combination with custom payment data. Example applications of this are Whatsat and TLV Shop.
Those who have been following multi-path payment development in Lightning for a while may be familiar with the AMP proposal, which has similarities to MPP, but which also features spontaneous payments. In this release, spontaneous multi-path payments aren’t yet supported.
Multi-Loop Out
Another exciting feature that is now close to release is Multi-Loop Out. With this, users can complete their Loop Out payment to the server using multiple channels at the same time. Imagine a merchant who at the end of the day loops out all of the day’s revenue straight into an exchange deposit address (or cold wallet) with one single sweep transaction. A similar upgrade exists for Loop In, but this still needs some work and will be released further down the line.
Getting started
To make a multi-path payment, the receiver must at least be running LND 0.9. That is the first version to include multi-path receiver support. An invoice can be created as usual.
On the sender side, lncli can be used as before with payinvoice or
sendpayment. However, payments will be single-shot by default. To enable
multi-path, the aforementioned maximum parts limit needs to be set to a value
higher than one. The corresponding command line flag is --max_parts.
Sending MPPs via the gRPC interface is only possible via the router subserver
call SendPaymentV2. We are
targeting this call to become the main payment RPC and plan to deprecate the
other legacy variations. This new version fills many gaps in the existing API
and allows picking up payment tracking after restarts, amongst other
enhancements.
Conclusion
It is probably clear by now that multi-path payments have been a relatively complex feature to implement. We are at the edge of what is currently known and are exploring as we go. Therefore, feedback on the performance of the current implementation and/or suggestions for next steps are very welcome. We are as always available on Slack and Github.
And remember: Lightning is a marathon and as long as we keep running, we will get to the finish line!
